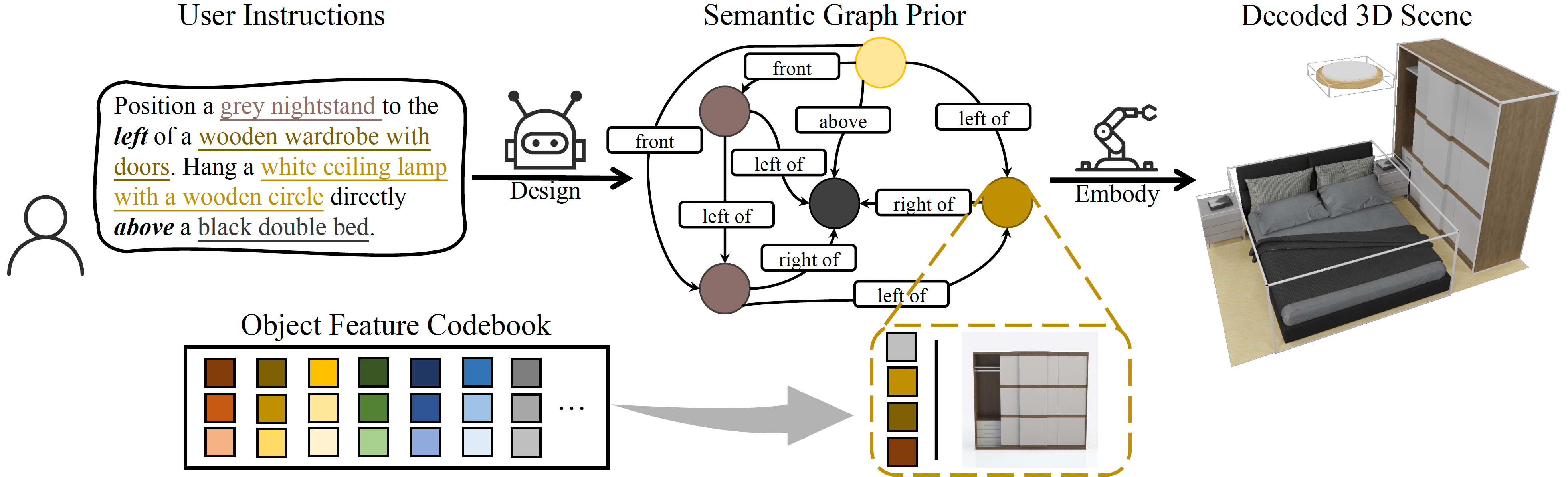
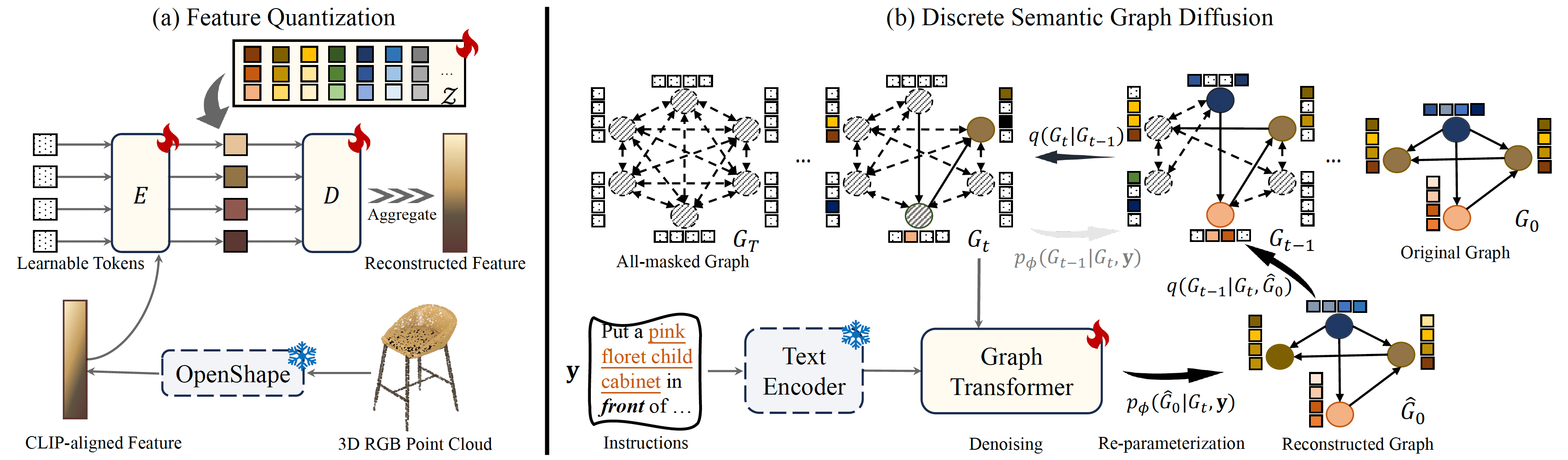
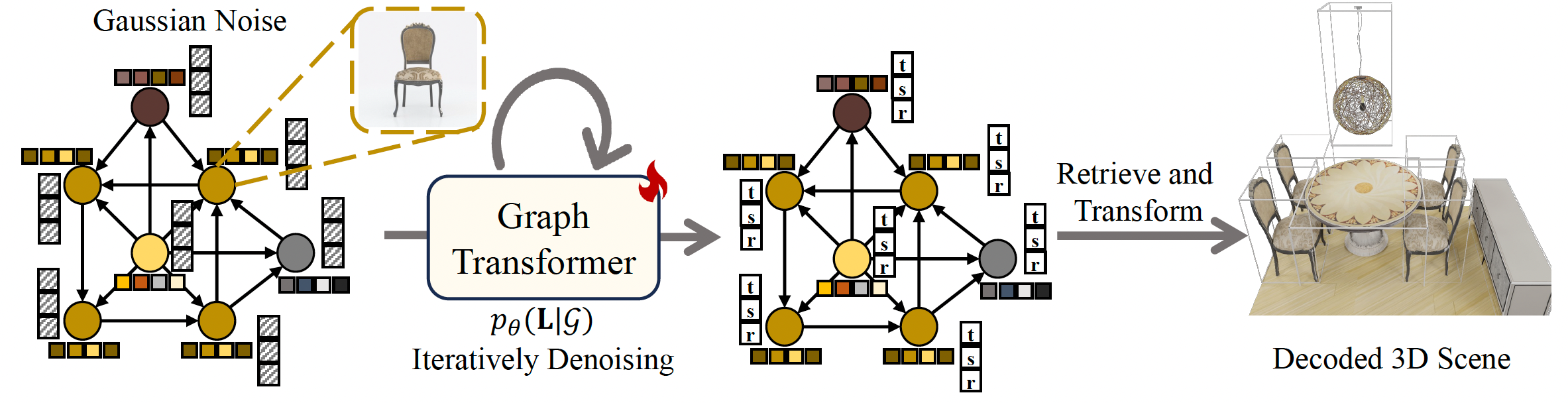
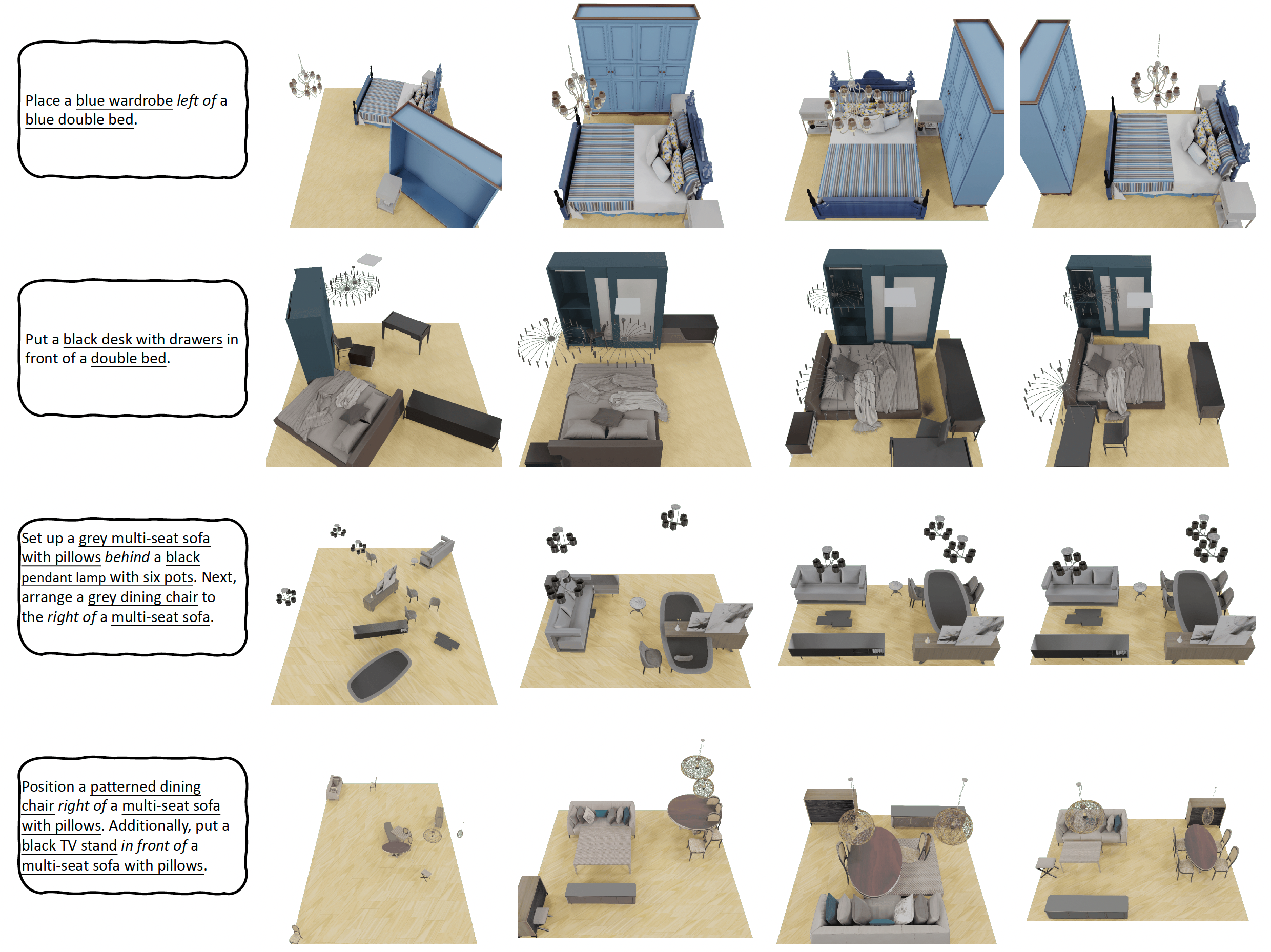
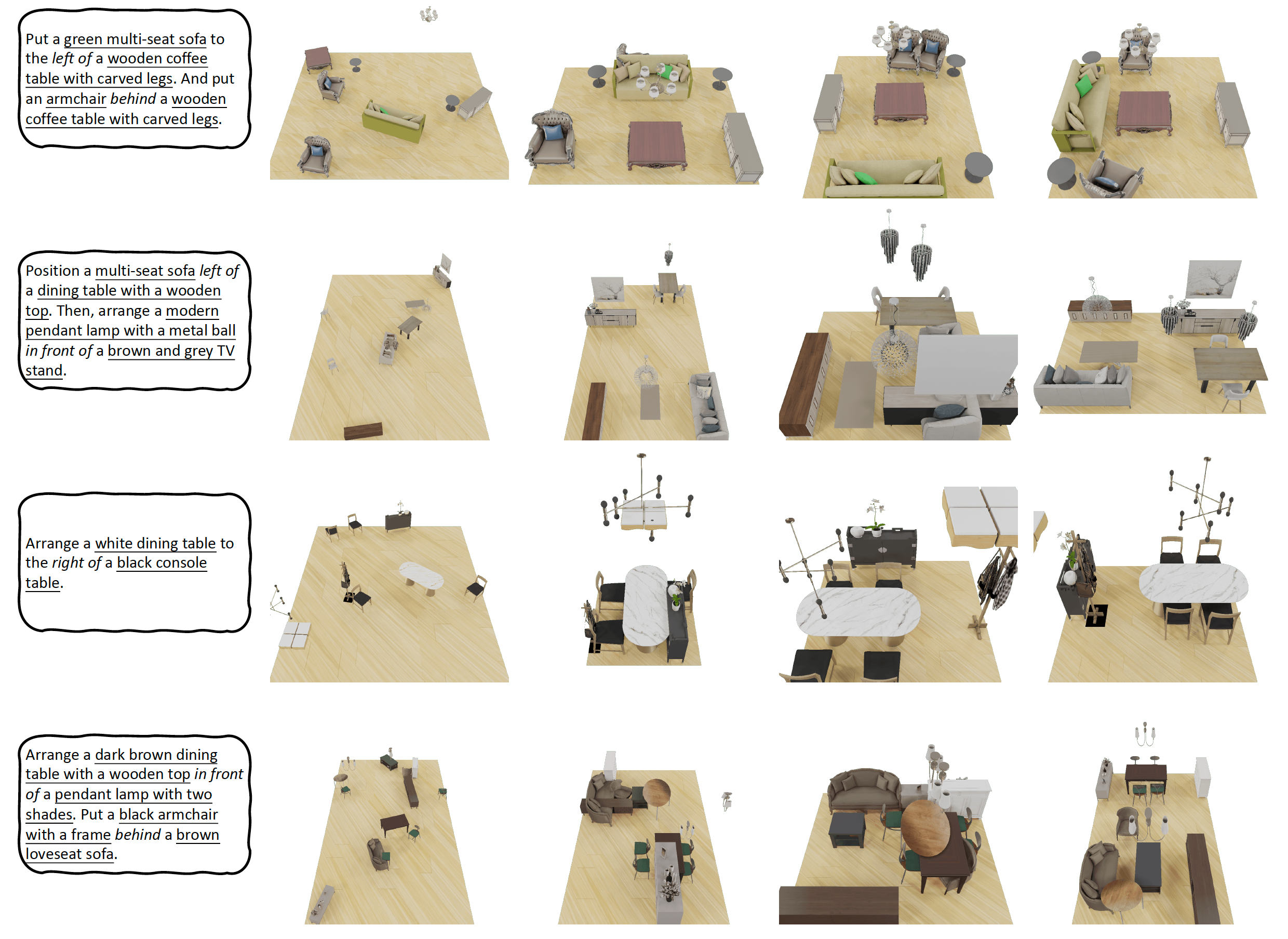
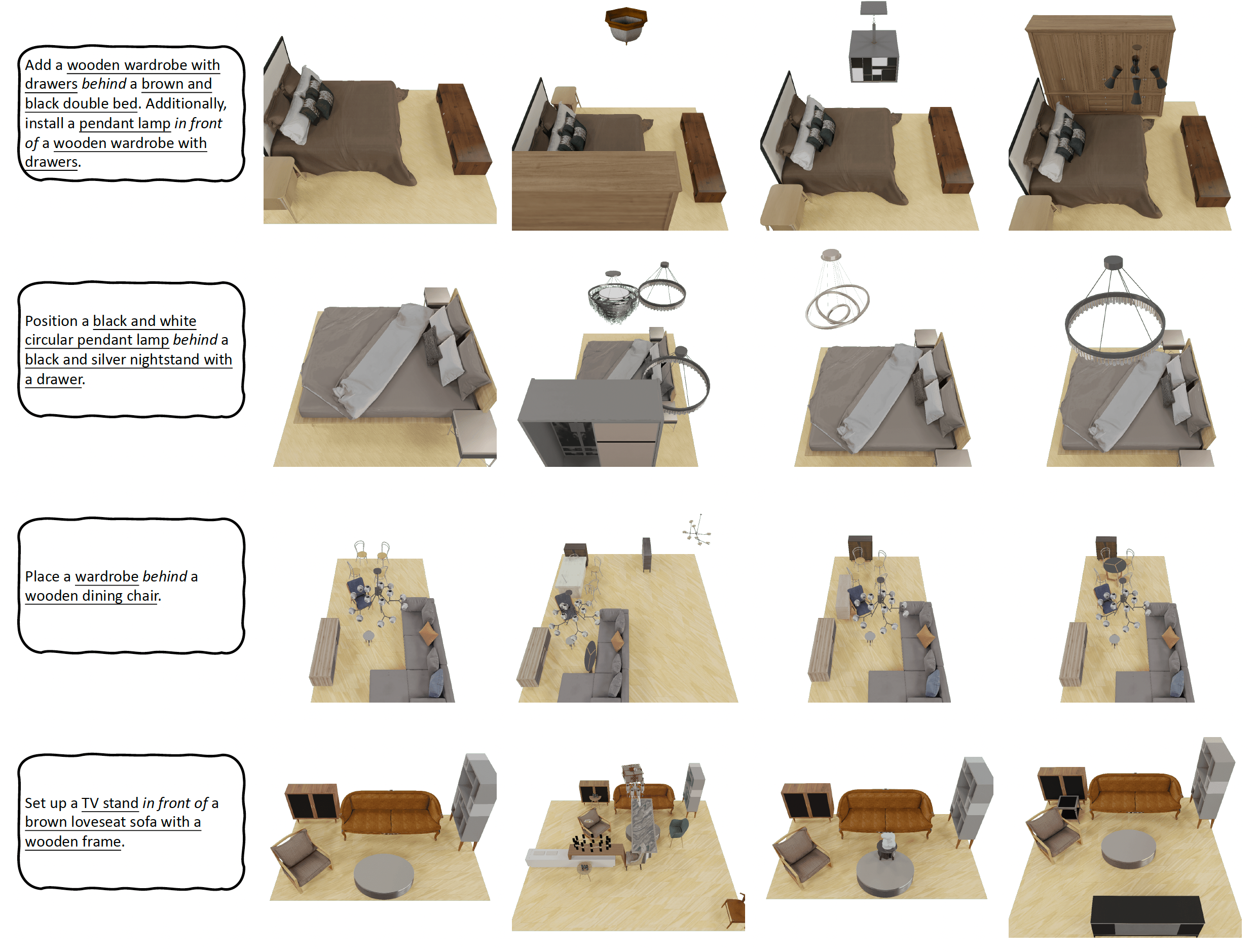
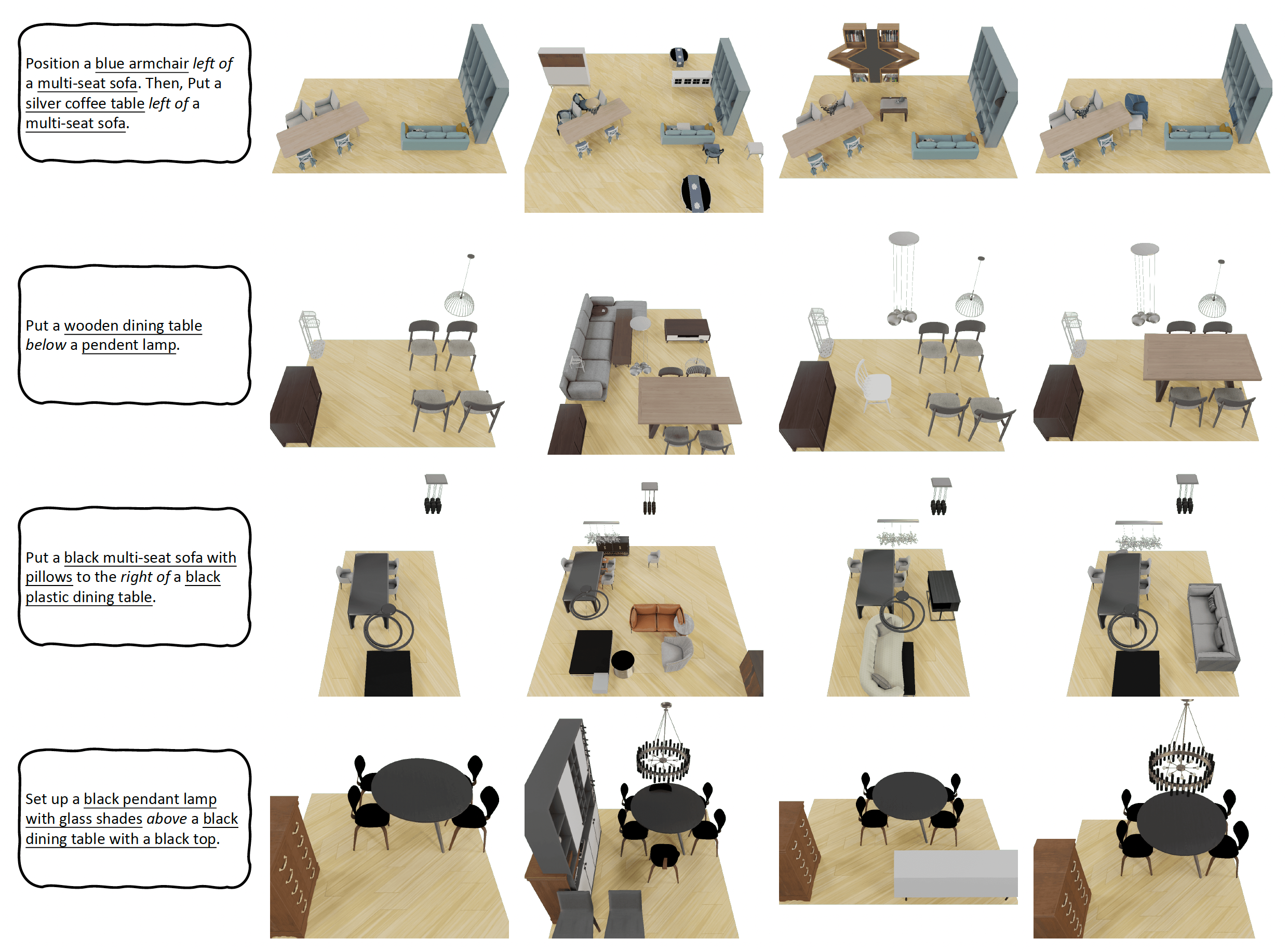
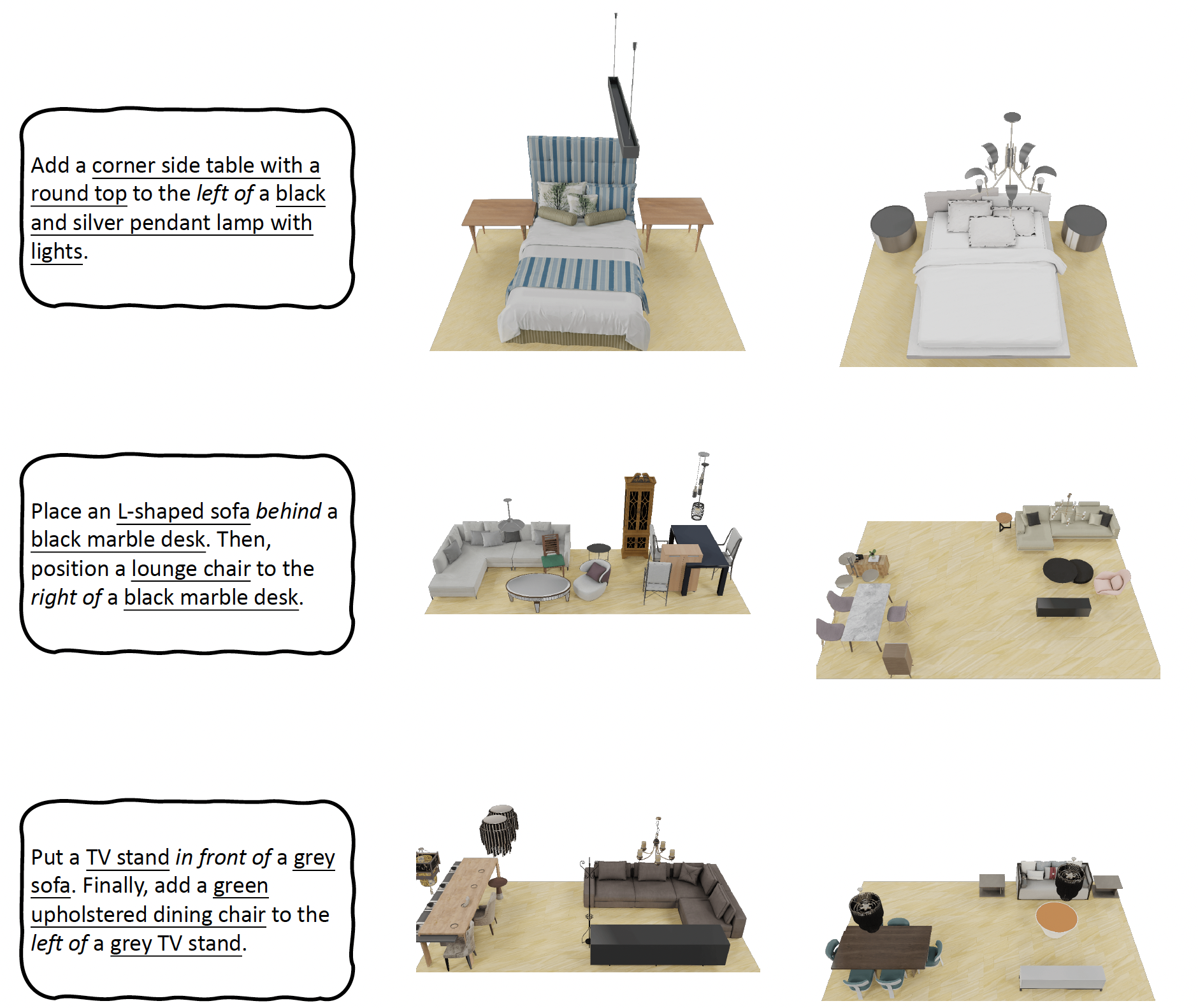
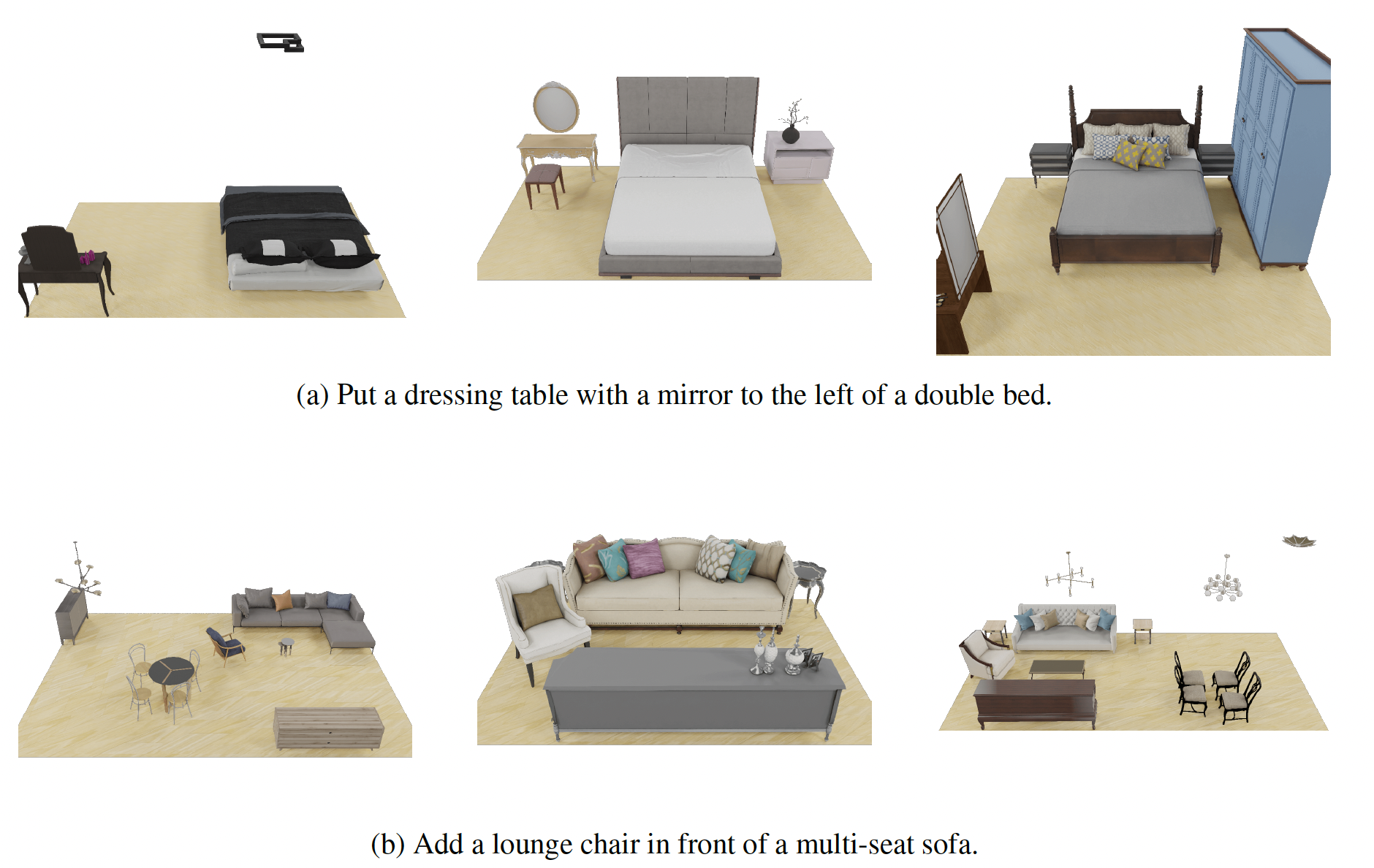
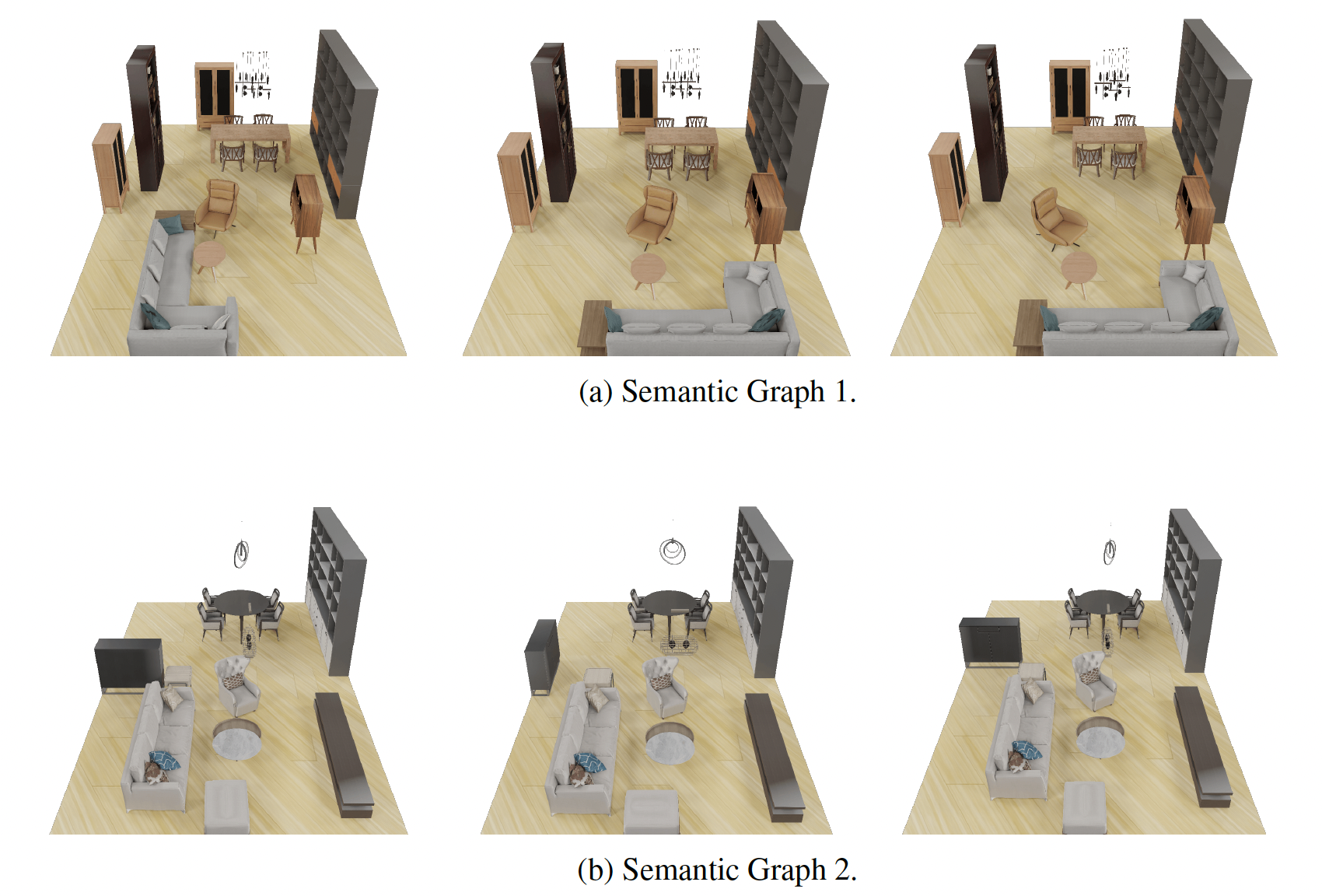
Comprehending natural language instructions is a charming property for 3D indoor scene synthesis systems. Existing methods (e.g., ATISS and
DiffuScene) suffer from directly modeling the object distributions within a scene, thereby hindering the controllability of generation.
We introduce InstructScene, a novel generative framework that integrates a semantic graph prior and a layout decoder to
improve controllability and fidelity for 3D scene synthesis. The proposed semantic graph prior jointly learns indoor scene appearance and layout distributions,
exhibiting versatility across various generative tasks. To facilitate the benchmarking for text-driven 3D scene synthesis, we curate a high-quality dataset of scene-instruction pairs with large language and multimodal models.
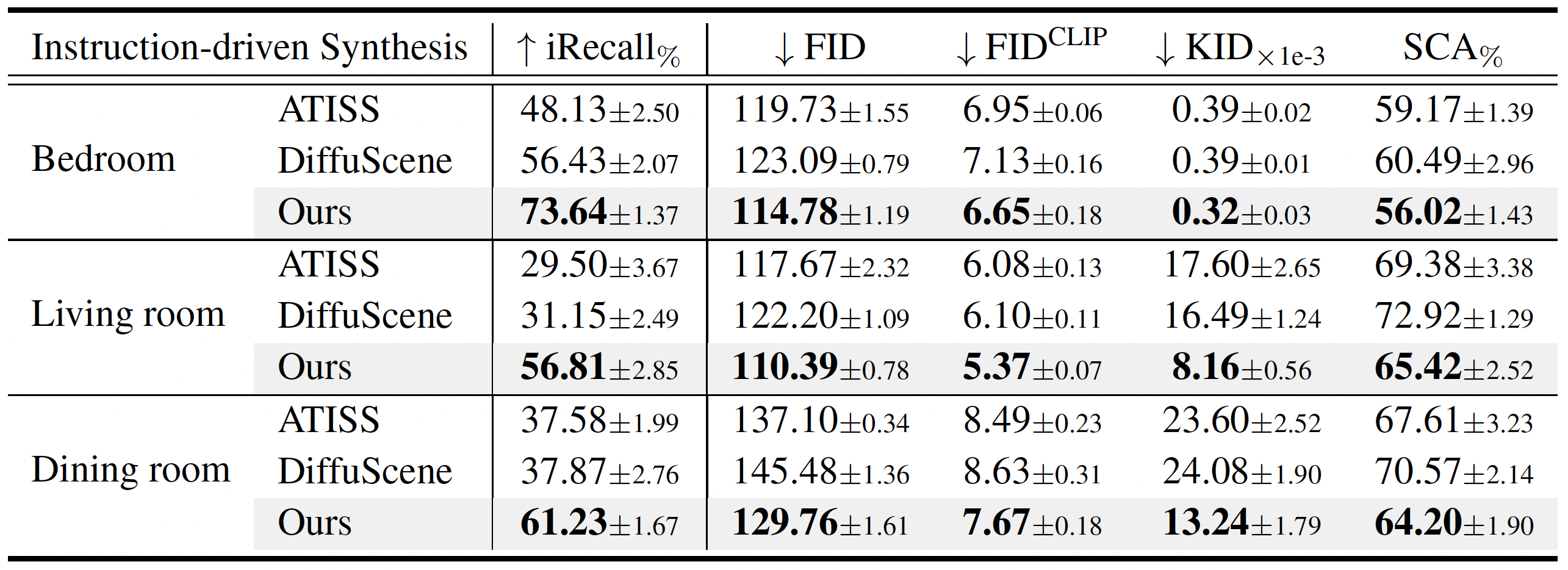
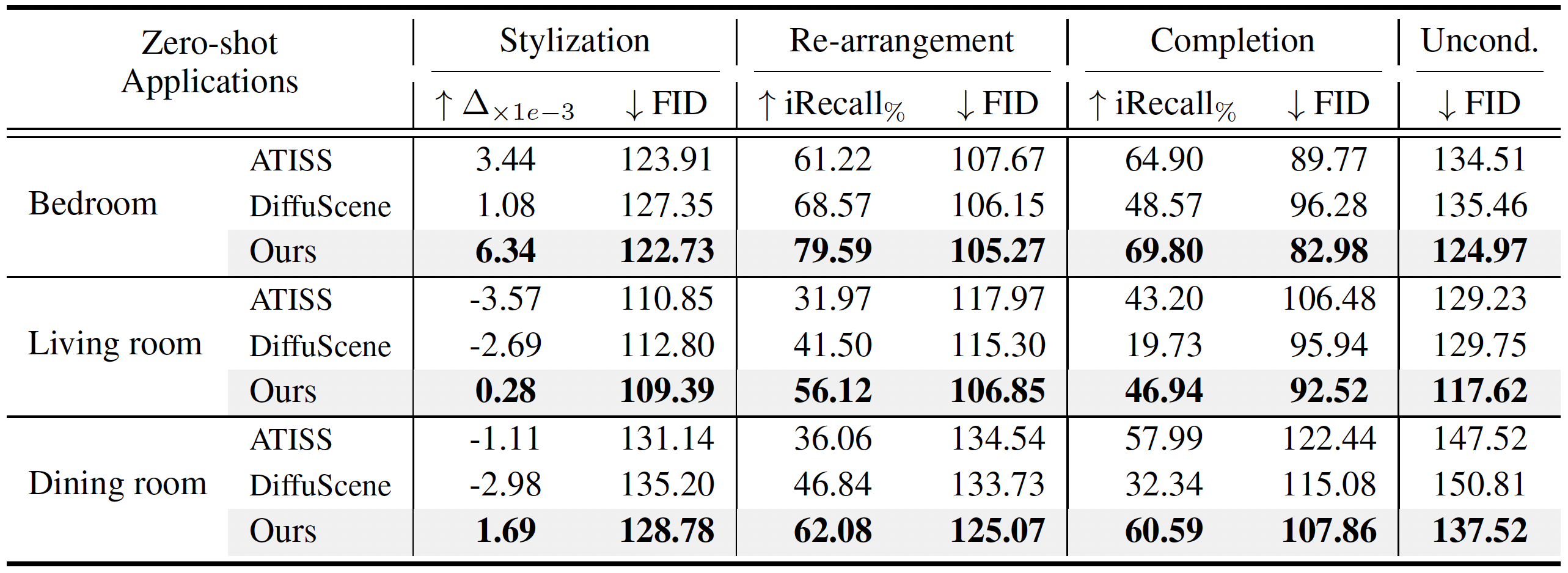
Extensive experimental results reveal that the proposed method surpasses existing state-of-the-art approaches by a large margin. Thorough ablation studies confirm the efficacy of crucial design components. Our code and dataset are available at
here.